📌 대입하는 숫자 값이 int 자료형의 최대값보다 큰 경우 long 사용 long 변수에 값을 대입할 때는 값 뒤에 L 접미사 붙여야 에러 발생X
1-1. 정수 오버플로우 / 언더플로우
데이터 표현 범위를 벗어남 → 전혀 다른 값(데이터손실) ∴ 데이터의 최소/최대 크기 고려
오버플로우 : 해당 타입이 표현할 수 있는 '최대 표현 범위'보다 큰 수를 저장할 때 발생
언더플로우 : 해당 타입이 표현할 수 있는 '최소 표현 범위'보다 작은 수를 저장할 때 발생
1-2. 언더스코어 표기법(underscore)
(jdk 7~ 지원) 큰 숫자 표기시 밑줄 문자로 구분 가능 - ex) 10_000_000_000_000
1-3. 2진수 / 8진수 / 16진수 표현
// 2진수 : 0b 로 시작
int a 0b101110
System.out.println(a); // 46
// 8진수 : 0 으로 시작
int b = 056;
System.out.println(b); // 46
// 16진수 : 0x 로 시작
int c = 0x2E;
System.out.println(c); // 46
2. 실수 자료형
실수형 타입
메모리의 크기
데이터의 표현 범위
리터럴 타입 접미사
float
4바이트
(3.4 X 10^-38) ~ (3.4 X 10^38)
F 또는 f
double
8바이트
(1.7 X 10^-308) ~ (1.7 X 10^308)
D 또는 d (생략 가능함)
📌 float 변수에 값을 대입할 때는 값 뒤에 F접미사(또는 소문자 f)
2-1. 실수의 표현 오차
한정적인 메모리로 인해 실수의 소숫점을 표현할 수 있는 수 제한
소수를 이진법으로 표현시 부동 소수점 방식 이용 → 정밀한 소수 표현 & 실수의 부정확한 연산 최소화
부동 소수점 방식도 완전히 정확하게 표현하는 것은 아니라 오차는 필연적으로 발생
2-2. 실수의 유효 자릿수 (정밀도)
실수의 소수 자리를 표현 : 타입별 유효 자릿수 제한이 존재
유효자릿수는 소수점 이하 자리수를 뜻하는 것이 아니라 좌측부터의 숫자 갯수를 의미
실수형 타입
지수의 길이
가수의 길이
유효 자릿수
float
8 bit
23 bit
소수점약 6~7자리까지 높은 확률로 정확히 표현
double
11 bit
52 bit
소수점 약 15~16자리까지 높은 확률로 정확히 표현
⇒ 부동소수점 표현 방식에 따른 결과 (가수부를 표현할 수 있는 크기에 따라 결정)
유효 자릿수 구하는 방법 - float형 : log10(2^23) = 7.224... (약7자리) - double형 : log10(2^52) = 15.653...(약15자리)
이 유효자릿수는 곧 실수의 정밀도를 의미
📌 정밀도 : 자릿수까지 변수에 저장된 값을 보장하는 것
📌 실수형의 선택 기준 - double : 보다 정확한 실수의 정밀도 필요시 - float : 산속도의 향상이나 메모리를 절약시
2-3. 실수 오버플로우 / 언더플로우
실수형에서도 변수의 값이 표현범위의 최댓값을 벗어나면 오버플로우 발생
오버플로우가 발생하면 변수의 값은 무한대(infinity)
언더플로우는 실수형으로 표현할 수 없는 아주 작은 값, 즉 양의 최솟값보다 작은 값이 되는 경우, 값은 0
오버 플로우 : 무한대 (infinity)
언더 플로우 : 양의 최소값보다 작은 값으로 0이 된다.
2-4. 지수(e) 표기법
아주 큰 숫자나 아주 작은 숫자를 간단하게 표기할때 사용되는 표기법
과학적 표기법(scientific notation)
길다란 실수 숫자를 나타내는 데 필요한 자릿수를 줄여 표현
3. 논리형 자료형
논리형(불리언) 자료형 : 참(true) 또는 거짓(false)의 값을 갖는 자료형
논리형 타입
할당되는 메모리의 크기
데이터의 표현 범위
boolean
1바이트
true, false
문자 자료형
한 개의 문자 값에 대한 자료형은 char 를 이용
문자값은 ' (단일 인용부호)로 감싸주어야 함 - " 쌍따옴표를 사용하면 에러 발생(" 는 문자열)
문자형 타입
할당되는 메모리의 크기
데이터의 표현 범위
char
2바이트
0 ~ 65,535
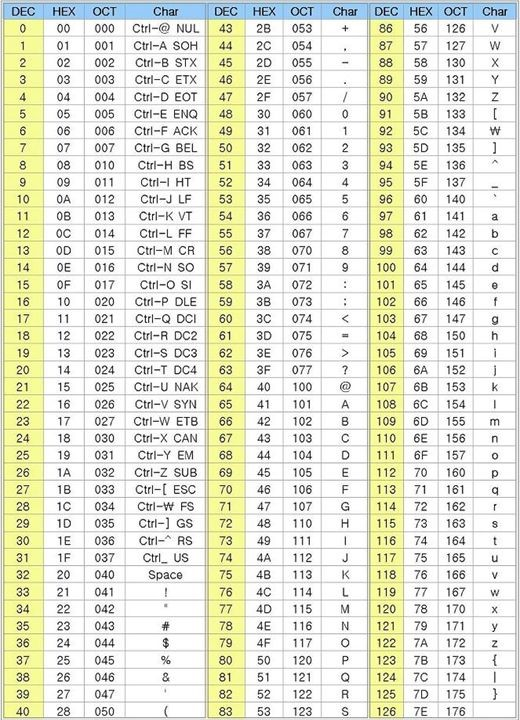
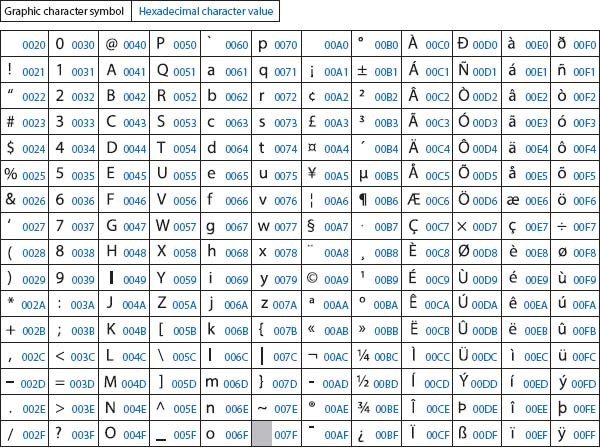
📌 아스키코드 - 1962년 안시(ANSI)가 정의한 미국 표준 정보교환 코드 - 1963년 미국표준협회(ASA)에 의해 결정되어 미국의 표준 부호가 됨 - 7비트의 이진수 조합으로 만들어져 총 128개의 부호 표현 가능 - 아스키코드의 처음 32개(0~31)는 프린터나 전송 제어용으로 사용 - 나머지는 숫자와 로마 글자 및 도량형 기호와 문장 기호를 나타냄
📌 유니코드 - 영어, 숫자, 기본적인 기호뿐만 아니라 그 나라, 그 언어에서 쓰는 다양한 문자들 처리해야 함 ⇒ 1바이트로 정의된 아스키 코드 확장 필요 - 각 나라별 언어를 모두 표현하기 위해 나온 코드 체계 - 사용 중인 운영체제, 프로그램, 언어에 관계없이 문자마다 고유한 코드 값을 제공 ⇒ 언어와 상관없이 모든 문자를 16비트로 표현 ⇒ 최대 65,536자까지 포현 가능
문자열 자료형
문자열 = 문장
문자는 하나의 글자로 작은 따옴표로 감싸고, 문자열은 글자의 집합으로서 쌍 따옴표로 감싸야 함
자바스크립트나 파이썬 같은 언어는 문자와 문자열 구분 but 자바는 이 둘을 엄격히 구분
String 클래스
C언어 : 문자열을 char형 배열로 표현 ↔ 자바 : 문자열을 위한 String이라는 클래스를 별도로 제공
String도 char[] 배열로 이루어진 데이터 자료
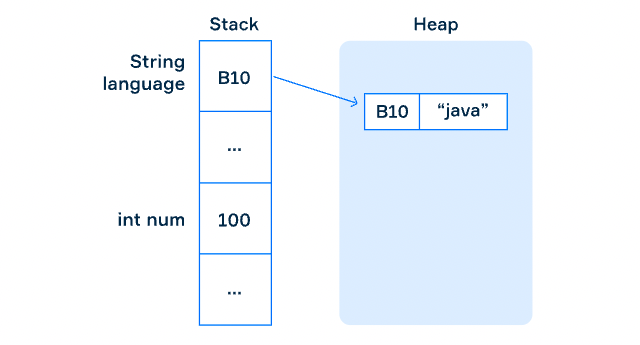
int, double, char는 원시(primitive) 자료형 ⇒ stack 영역에 그대로 저장 String 자료형은 참조(reference) 자료형 ⇒ 데이터(문자열)는 heap 영역에 저장, 주소만 stack 영역에 저장
문자열 내장 메소드
String 클래스에는 문자열과 관련된 작업을 할 때 유용하게 사용할 수 있는 다양한 메소드 有
메서드
설명
String(String s)
문자열 s에 대한 String 인스턴스 생성
String(char[] value)
문자 배열 value를 갖는 String 인스턴스 생성
String(StringBuffer buf)
StringBuffer 인스턴스 buf와 같은 내용의 String 인스턴스 생성
char charAt(int index)
지정된 위치 index(0부터시작하는 위치)의 문자를 리턴합니다.
int compareTo(String anotherString)
두 문자열을 사전식 순서로 비교하여 결과를 리턴합니다. 같다면 0, 호출한 문자열이 작으면 음수, 크면 양수 값을 리턴합니다.
boolean endsWith(String suffix)
문자열이 지정한 문자열로 끝나는지 검사하여 결과를 리턴합니다.
boolean equals(Object obj)
두 문자열의 내용이 같은지 검사하여 결과를 리턴합니다.
boolean startsWith(String prefix)
문자열이 지정한 문자열로 시작하는지 검사하여 결과를 리턴합니다.
int indexOf(String str)
문자열에서 지정한 문자열이 시작되는 첫 번째 위치를 리턴합니다. 없으면 -1을 리턴합니다.
int length()
문자열의 길이를 리턴합니다.
String replace(char oldChar, char newChar)
문자열에서 oldChar를 찾아 newChar로 변경한 문자열을 리턴합니다.
String toLowerCase()
문자열의 모든 문자를 소문자로 변환한 문자열을 리턴합니다.
String toUpperCase()
문자열의 모든 문자를 대문자로 변환한 문자열을 리턴합니다.
String substring(int beginIndex)
문자열에서 지정된 위치(beginIndex)부터 끝까지의 모든 문자를 포함하는 문자열을 리턴합니다.
String substring(int beginIndex, int endIndex)
문자열에서 지정된 범위(beginIndex부터 endIndex까지)의 문자들을 포함하는 문자열을 리턴합니다. endIndex는 포함되지 않습니다.
String[] split(String regex)
문자열을 주어진 정규표현식(regex)을 기준으로 분리하여 문자열 배열로 리턴합니다.
String trim()
문자열 양 끝의 공백을 제거한 문자열을 리턴합니다.
byte[] getBytes()
문자열을 바이트 배열로 변환하여 리턴합니다. 보통 인코딩 작업 시 사용됩니다.
boolean contains(CharSequence s)
문자열이 주어진 문자열(s)을 포함하는지 확인하여 결과를 리턴합니다.
String[] split(String regex, int limit)
문자열을 지정한 정규표현식(regex)을 기준으로 최대 limit 개수만큼 분할하여 문자열 배열로 리턴합니다.