1-1. 데이터 분석 기법의 이해
| 1. 데이터 처리 과정 | • 데이터 분석을 위해서 데이터웨어하우스(DW)나 데이터마트(DM)를 통해 분석데이터 구성 • 신규데이터나 DW에 없는 데이터는 기존 운영시스템(Legacy)에서 직접 가져오거나 운영데이터저장소(ODS)에서 정제된 데이터를 가져와서 DW의 데이터와 결합하여 활용 |
| 2. 시각화 기법 | • 가장 낮은 수준의 분석 but 잘 사용하면 복잡한 분석보다 더 효율적 • 대용량 데이터를 다룰 때 & 탐색적 분석을 할 때 필수 |
| 3. 공간 분석 | • 공간적 차원과 관련된 속성들을 시각화하는 분석 • 지도 위에 관련된 속성들을 생성하고 크기모양, 선 굵기 등을 구분하여 인사이트를 얻음 |
| 4. 탐색적 자료 분석 (EDA) |
• 다양한 차원과 값을 조합해가며 특이점이나 의미있는 사실 도출하여 최종 목적에 달성하는 과정 • EDA의 4가지 주제 : 저항성의 강조, 잔차 계산, 자료변수의 재표현, 그래프를 통한 현시성 |
| 5. 통계 분석 | • 어떤 현상을 종합적으로 한눈에 알아보기위해 일정한 체계에 따라 숫자와 표, 그림의 형태로 나타낸 것 |
| 6. 데이터 마이닝 | • 대용량의 자료로부터 정보를 요약하고 미래에 대한 예측을 목표로 자료에 존재하는 관계, 패턴, 규칙 등을 탐색하고 이를 모형화함으로써 이전에 알지 못한 유용한 지식을 추출 • 방법론 : 기계학습(인공신경망, 의사결정나무, 클러스터링, SVM), 패턴인식(연관규칙, 장바구니분석) |
2-1. R 소개
01. R의 탄생
- 오픈소스 프로그램
- 통계, 데이터마이닝과 그래프를 위한 언어
- 다양한 최신 통계분석과 마이닝 기능 제공(5,000개에 이르는 패키지가 수시로 업데이트)
02. 통계분석 도구의 비교
| 구분 | SAS | SPSS | R |
| 프로그램 비용 | 유료, 고가 | 유료, 고가 | 오픈소스 |
| 설치 용량 | 대용량 | 대용량 | 모듈화로 간단 |
| 다양한 모듈 지원 및 비용 | 별도구매 | 별도구매 | 오픈소스 |
| 최근 알고리즘 및 기술반영 | 느림 | 다소 느림 | 매우 빠름 |
| 학습자료 입수의 편의성 | 유료 도서 위주 | 유료 도서 위주 | 공개 논문 및 자료多 |
| 질의를 위한 공개 커뮤니티 | 없음 | 없음 | 매우 활발 |
03. R의 특징
- 오픈소스 프로그램
- 뛰어난 그래픽 및 성능
- 시스템 데이터 저장 방식
- 모든 운영체제에서 사용 가능(윈도우, 맥, 리눅스)
- 표준 플랫폼(S 언어 기반)
- 객체 지향언어이면서 함수형 언어
2-2. R 기초
01. 편리한 기능
- R의 작업환경 설정 : R 단축아이콘 우클릭 → 속성 → 바로가기 → 시작위치에 현재 작업위치를 입력 → 저장
- 프로그램에서 작업환경 설정 : setwd("작업디렉토리")
- 도움말 : help(함수), ?함수, RSiteSearch("함수명")
- 히스토리 : history(), savehistory(file="파일명"), loadhistory(file="파일명")
- 콘솔 청소 : Ctrl + L
02. 스크립트 사용하기
- 한줄 실행 : Ctrl + R
- 여러줄 실행 : 드래그 후 Ctrl + R
- 주석처리 : #
03. 패키지
- 패키지 : R 함수, 데이터 및 컴파일 코드의 모임
- 패키지 자동설치 : install.packages("패키지명")
- 패키지 수동설치 : install.packages("패키지명","패키지 위치")
04. 배치 실행
- 매일 실행되어야하는 프로그램을 시스템의 프로세스에서 자동으로 구동하는 작업
- 배치파일 실행 명령 : 윈도우 창에서 batch.R 실행파일이 있는 위치에서 R CMD BATCH batch.R
- Path 지정 : 내컴퓨터에 우클릭 → 속성 → 고급시스템 설정 → 환경변수 → 변수명 path 선택 → R프로그램의 실행파일의 위치를 찾아서 추가 → 저장
05. 변수 다루기
- R에서는 변수명만 선언하고 값을 할당하면 자료형태를 스스로 인식하고 선언함
- 화면에 프린트하고자 할 때, print()를 사용해도 되지만 변수 값만 표현해도 내용을 출력함
- 변수에 값을 할당할 때는 대입연산자(<-,<<-,=,->,->>)를 사용할 수 있으나 <-를 추천함
- 메모리에 불필요한 변수가 있는지 확인하기 위해서는 is()를 활용하고 삭제는 rm()을 활용함
06. 기본적인 통계량 계산
| 기능 | 함수 | 기능 | 함수 |
| 평균 | mean() | 중앙값 | median() |
| 표준편차 | sd() | 분산 | var() |
| 공분산 | cov() | 상관계수 | cor() |
07. 함수의 생성 및 활용
- R은 함수형 언어이기 때문에 프로그래머가 직접 활용 가능한 함수를 생성하여 활용 가능
- 함수는 function(매개변수1, 매개변수2, ...) 로 선언하고 표현식이 2줄 이상인 경우에는 {}로 묶어서 범위 설정
- 표현식은 변수 할당, 조건문(if문)과 반복문(for문, while문, repeat문), 전달값(return)으로 구성
08. 연산자 우선순위
| 연산자 우선순위 | 뜻 | 사용 예시 |
| [ [[ | 인덱스 | a[1] |
| $ | 요소 or 슬롯 뽑아내기 | a$coef |
| ^ | 지수 | 5^2 |
| - + | 단항 마이너스와 플러스 부호 | -3, +5 |
| : | 수열 생성 | 1:10 |
| %any% | 특수 연산자 | %/% 나눗셈 몫, %%나눗셈 나머지, %*% 행렬의 곱 |
| * / | 곱하기, 나누기 | 3*5, 3/5 |
| + - | 더하기, 빼기 | 3+5, 3-5 |
| == != <> <= => | 비교 | 3==5 |
| ! | 논리 부정 | |
| & | 논리 "and", 단축(short-circuit) "and" | TRUE & TURE |
| | | 논리 "or", 단축(short-circuit) "or" | TRUE | TRUE |
| ~ | 식(formula) | lm(log(brain)~log(body),data=Animals) |
| -> ->> | 대입(왼쪽을 오른쪽으로) | 3->a |
| = | 대입(오른쪽을 왼쪽으로) | a=3 |
| <- <<- | 대입(오른쪽을 왼쪽으로) | a<-3 |
| ? | 도움말 | ?lm |
09. R의 정규분포 함수
- rnorm(난수함수)
- dnorm(확률밀도함수)
- pnorm(누적분포함수)
- qnorm(분위수함수)
✔ 알파벳 r, d, p, q 가 의미하는 것 출제
2-3. 입력과 출력
01. 데이터 입력과 출력
- R에서는 텍스트 데이터 뿐만 아니라 데이터베이스와 다양한 통계프로그램에서 작성된 데이터를 불러들여서
적절한 데이터 분석 수행 가능 - 부동소수점 표현시 7자리 수가 기본 셋팅되어있음
option()함수, digit="숫자"를 지정해 자릿수 변경 가능 - 문자열을 파일로 저장 : cat("저장할 문자열", file="파일명")
- 역슬래쉬(\) 인식 불가 → 슬래쉬(/) or 이중 역슬래쉬(\\)로 파일 경로 지정
02. 외부 파일 입력과 출력
| 고정자리 변수 파일 | read.fwf("파일명", width=c(w1, w2, ...)) |
| 구분자 변수 파일 | read.table("파일명", sep="구분자") |
| csv 파일 읽기 | read.csv("파일명", header=T) # 1행이 변수인 경우 : header=T |
| csv 파일 출력 | write.csv(데이터 프레임, "파일명") |
03. 웹페이지(Web Page)에서 데이터 읽어오기
| 파일 다운로드 | read.csv("http://www.example.com/download/data.csv") |
| ftp에서 파일 다운로드 | read.csv("ftp://ftp.example.com/download/data.csv") |
| html에서 테이블 | readHTMLTable("url") |
2-4. 데이터 구조와 데이터 프레임
01. 데이터 구조의 정의
| 특징 | 벡터 | 리스트 | 데이터 프레임 |
| 원소 자료형 | 동질적 | 이질적 | 이질적 |
| 원소를 위치로 인덱싱 | 가능 | 가능 | 가능 |
| 인덱싱으로 여러개 원소로 구성된 하위 데이터 생성 |
가능 | 가능 | 가능 |
| 원소들에 이름 부여 | 가능 | 가능 | 가능 |
| 단일값(Scalar) | 원소가 하나인 벡터로 인식/처리 |
| 행렬(Matrix) | 원소가 하나인 벡터로 인식/처리 |
| 배열(Array) | 3원소가 하나인 벡터로 인식/처리 |
| 요인(Factor) | 유일값이 요인의 수준(Level)으로 구성된 벡터(범주형 변수, 집단 분류) |
| 데이터 프레임 | 벡터 |
| iris[1,] iris[,c(1,2)] iris[1] iris["Sepal.Length"] ⇐ 변수의 이름과 값이 같이 출력 |
iris[[1]] iris$Sepal.Length ⇐ 데이터$변수 : 변수를 값으로만 출력 iris[["Sepal.Length"]] iris[,1] |
✔ 데이터 프레임, 벡터 인덱싱 구분
02. 리스트 다루기
- 리스트 원소 선택 : L[[n]], L[["name"]], L$name
03. 행렬 다루기
- 행렬 설정 : dim(vec) <- c(2, 3)
- 행과 열 이름 붙이기 : rownames(mtrx) <- c("rowname1", "rowname2", ...)
colnames(mtrx) <- c("colname1", "colname2", ...)
04. 데이터 구조 변환
| 변환 | 방법 | 변환 | 방법 |
| 벡터 → 리스트 | as.list(vec) | 행렬 → 벡터 | as.vector(mat) |
| 벡터 →행렬 | 1열짜리 : cbind(vec) or as.matrix(vec) 1행짜리 : rbind(vec) n x m : matrix(vec, n, m) |
행렬 → 리스트 | as.list(mat) |
| 백터 → 데이터 프레임 | 1열짜리 : as.data.frame(vec) 1행짜리 : as.data.frame(rbind(vec)) |
행렬 → 데이터 프레임 | as.data.frame(mat) |
| 리스트 → 벡터 | unlist(lst) | 데이터 프레임 → 벡터 | 1열짜리 : dfm[[1]] or dfm[,1] 1행짜리 : dfm[1,] |
| 리스트 → 행렬 | 1열짜리 : as.matrix(lst) 1행짜리 : as.matrix(rbind(lst)) n x m : matrix(lst, n, m) |
데이터 프레임 → 리스트 | as.list(dfm) |
| 리스트 → 데이터 프레임 | 목록 원소들이 데이터의 열 : as.data.frame(lst) 리스트 원소들이 데이터의 행 : rbind(obs[[1]], dbs[[2]]) |
데이터 프레임 → 행렬 | as.matrix(dfm) |
05. 집단으로 분할하기
- 벡터 : split(vec, fac) - 벡터값과 팩터값의 길이가 같아야 함
- 데이터프레임 : split(dfm, fac)
06. 함수 적용하기
- 벡터 : 행렬 : apply(mtr, 1, func), apply(mtr, 2, func)
- 리스트 : lapply(lst, func), sapply(lst, func)
- 데이터 프레임 : lapply(dfm, func), sapply(dfm, func), apply(dfm, 1or2, func)
07. 집단별로 함수 적용하기
- tapply(vec, fac, func)
- by(dfm, fac, func)
08. 병렬 벡터들과 리스트들에 함수 적용하기
- 벡터 : mapply(func, vec1, vec2, vec3, ...)
- 리스트 : mapply(func, lst1, lst2, lst3, ...)
09. 문자열 다루기
| 문자열 길이 | nchar("문자열") |
| 벡터의 길이 | length(vec) |
| 문자열 연결하기 | paste("단어", "문장", scalar) |
| 하위 문자열 추출하기 | substr("문자열", 시작번호, 끝번호) |
| 구분자로 문자열 추출하기 | strsplit("문자열", 구분자) |
| 문자열 대체하기 | sub("대상문자열", "변경문자열", s), gsub("대상문자열", "변경문자열", s) |
10. 날짜 다루기
- 문자열 → 날짜 : as.Date("2024-12-25")
as.Date("12,25,2024", format="%m/%d/%Y") - 날짜 → 문자열 : format(Sys.Date(), format ="%m/%d/%Y")
- format 인자값
| R 표현 | 표시 형태 | R 표현 | 표시 형태 |
| %b | 축약된 월 이름("Jan") | %B | 전체 월 이름("January") |
| %d | 두 자리 숫자로 된 일("31") | %m | 두 자리 숫자로 된 월("12") |
| %y | 두 자리 숫자로 된 년("24") | %Y | 네 자리 숫자로 된 년("2024") |
11. 벡터의 연산(벡터들 길이가 동일하지 않은 경우)
- 두 벡터의 원소가 개수가 다르더라도 연산과정에서 원소의 개수가 적은 쪽의 벡터는 원소의 개수가 많은 쪽의 벡터와 동일하게 원소의 개수를 맞춤
- ex) x <- c(1,2,3) y<-(1, 2, 3, 4, 5, 6)
x + y 의 값은 2 4 6 5 7 9
✔ 단답형, 객관식으로 출제된 적 있음
12. 데이터 종류
- 한가지 유형 데이터 타입만 가능한 것은 벡터, 행렬, 배열
- 리스트, 데이터프레임, 데이터테이블은 복수의 데이터타입이 가능하기때문에 복합형이라고 한다
- R에서 결측값은 Na, NaN은 수학적으로 불가한 수를 표시할 때, NULL은 데이터 유형과 자료의 길이도 0인 비어있는 값을 의미
- 난수 발생시 동일한 난수가 발생되도록 초기화하는 R함수 : set.seed()
표본 무작위 추출시 괄호 안 아라비아숫자를 넣으면 같은 숫자끼리 동일한 표본 추출
✔ 데이터 유형 특징과 함수의 의미 출제
13. 데이터 분포의 흩어짐(산포)
- 변동계수 : 표준편차 / 평균, 측정단위가 서로 다른 데이터를 비교할 때 사용
- IQR(사분위수범위) : Q3 - Q1 상자그림에서 25% 위의 값 & 75% 아래의 값의 변동 확인 할 수 있는 값
- 범위 : 최대값 - 최소값
- 왜도 : 정규분포이면 왜도는 '0', '0'보다 크면 왼쪽으로 치우친 분포
- 첨도 : 첨도가 3보다 크면 정규분포보다 뾰족한 모양
✔ 용어문제 출제, 특히 사분위수 범위와 사분위수는 서로 다른 개념
14. 대푯값의 비교(평균, 중위수, 최빈치)
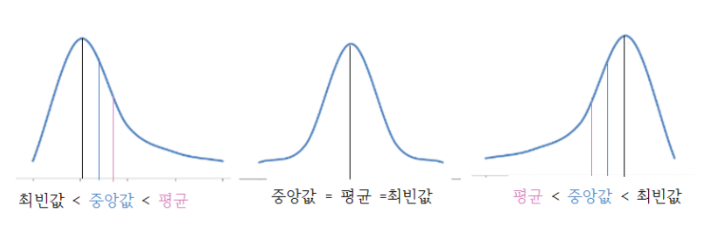
✔ 중앙값과 평균값 크기를 통해 비대칭도를 추정하는 객관형 문제 출제
15. BOXPLOT(상자그림)

- 하한값(최소값) = Q1(1사분위수) - 1.5*IQR(Q3-Q1)
- 상한값(최대값) = Q3(3사분위수) + 1.5*IQR(Q3-Q1)
- boxplot 으로 이상치 검색 가능
3-1. 데이터 변경 및 요약
01. 데이터 마트
- 데이터 웨어하우스와 사용자 사이의 중간층에 위치
- 하나의 주제 또는 하나의 부서 중심의 데이터 웨어하우스
- apply 함수에 기반해 데이터와 변수를 동시에 배열로 치환 split → apply → combine 기능 제공
즉, 데이터 분할 → 함수 적용 → 재결합
✔ plyr 패키지 기능
02. 요약변수와 파생변수
| 요약변수 | 파생변수 | |
| 정의 | • 수집된 정보를 분석에 맞게 종합한 변수 • 데이터 마트에서 가장 기본적인 변수 • 많은 모델이 공통으로 사용 가능 → 재활용성 높음 |
• 사용자(분석가)가 특정 조건을 만족하거나 특정 함수에 의해 값을 만들어 의미를 부여한 변수 • 주관적일 수 있으므로 논리적 타당성을 갖출 필요 있음 |
| 예시 | • 기간별 구매 금액, 횟수, 여부 / 위클리 쇼퍼 / 상품별 구매 금액, 횟수, 여부 / 상품별 구매 순서 / 유통 채널별 구매 금액 / 단어 빈도 / 초기 행동변수 / 트랜드 변수 / 결측값과 이상값 처리 / 연속형 변수의 구간화 |
• 근무시간 구매자수 / 주 구매 매장 변수 / 주 활동 지역 변수 / 주 구매 상품 변수 / 구매상품 다양성 변수 / 선호하는 가격대 변수 / 시즌 선호 고객 변수 / 라이프 스테이지 변수 / 라이프스타일 변수 / 휴면가망변수 / 최대가치 변수 / 최적 통화시간 등 |
03. reshape 패키지
- 2개의 핵심적인 함수로 구성
| melt() | 쉬운 casting을 위해 데이터를 적당한 형태로 만들어주는 함수 |
| cast() | 데이터를 원하는 형태로 계산 또는 변형시켜주는 함수 |
- 변수를 조합해 변수명을 만들고 변수들을 시간, 상품 등의 차원에 결합해 다양한 요약변수와 파생변수를
쉽게 생성하여 데이터마트를 구성할 수 있게 해주는 패키지

04. sqldf 패키지
- R에서 sql 명령어를 사용가능하게 해주는 패키지
- SAS의 proc sql 과 같은 기능
- head([df]) → sqldf("select * from [df] limit 6")
- subset([df], [col] %in% c("BF", "HF")) → sqldf("select * from [df] where [col] in('BF', 'HF')")
- merge([df1], [df2]) → sqldf("select * from [df1], [df2]")
05. plyr 패키지
- apply 함수를 기반으로 데이터와 출력변수를 동시에 배열로 치환하여 처리하는 패키지
- split - apply - combine 방식으로 데이터를 분리하고 처리한 후 다시 결합하는 필수적인 데이터 처리 기능 제공
| array | data frame | list | nothing | |
| array | aaply | adply | alply | a_ply |
| data frame | daply | ddply | dlply | d_ply |
| list | laply | ldply | llply | l_ply |
| n replicates | raply | rdply | rlply | r_ply |
| function arguments | maply | mdply | mlply | m_ply |
06. data.table 패키지
- R에서 가장 많이 사용하는 데이터 핸들링 패키지 중 하나
- 대용량 데이터의 탐색, 연산, 병합에 유용
- 기존 data.frame 방식보다 월등히 빠른 속도
- 특정 column을 key 값으로 색인을 지정한 후 데이터 처리
- 빠른 grouping과 ordering, 짧은 문장 지원 측면에서 데이터프레임보다 유용
07. 자료의 척도
- "명목척도는 중앙값 또는 평균계산이 가능" ← 오답 보기문제로 출제
- 명목척도는 이퀄(=)만 존재. 평균 계산 불가 - "구간척도는 측정대상이 갖고있는 속성의 질을 측정" ← 오답 보기문제로 출제(속성의 질→속성의 양)
- 구간척도는 측정 대상이 가지고 있는 양을 측정. 크기나 각각의 척도간의 간격 동일 - "구간척도는 절대 영점이 존재" ← 오답 보기문제로 출제(구간척도는 절대 영점 존재X)
- 구간척도는 곱하기, 나누기 불가
- 사칙연산이 모두 가능한 것은 비율척도밖에 없음
✔ 척도의 특징 출제
3-2. 데이터 가공
01. 변수의 구간화
- 신용평가모형, 고객 세분화 등의 시스템으로 모형 적용 ⇒ 각 변수들을 구간화하여 점수를 적용하는 방식 활용
- 변수의 구간화를 위한 rule 존재햄
- 10진수 단위로 구간화, 구간을 5개로 나누는 것이 보통 / 7개 이상의 구간을 잘 만들지 않음
02. 변수 구간화의 방법
| Binning | 연속형 변수를 범주형 변수로 변환하기 위해 50개 이하의 구간에 동일한 수의 데이터를 할당하여 의미를 파악하면서 구간을 축소하는 방법 |
| 의사결정나무 | 모형을 통해 연속형 변수를 범주형 변수로 변환하는 방법 |
3-3. 기초 분석 및 데이터 관리
01. 결측값 처리
(1) 결측값 처리
- 변수에 데이터가 비어있는 경우 NA, ., 99999999, Unknown, Not Answer 등으로 표현
- na.omit() # NA 가 있는 행 전체 삭제
- na.rm=TRUE # na.rm 은 NA 값이 있을 때 해당 값을 연산에서 제외할 것인지 결정하는데 사용
- boxplot() 시각화하기
boxplot(수치형자료 ~ 범주형자료, 데이터명) - 0/0 의 R 출력값은?
- NaN(Not a Number) : 정의되지 않거나 할 수 없는 연산으로 나타내는데 사용
(2) 단순 대치법(Single Imputation)
- Completes Analysis : 결측값의 레코드를 삭제
- 평균대치법 : 관측 및 실험을 통해 얻어진 데이터의 평균으로 대치
- 비조건부 평균 대치법 : 관측 데이터의 평균으로 대치
- 조건부 평균 대치법 : 회귀분석을 통해 데이터를 대치 - 단순 확률 대치법 : 평균대치법에서 추정량 표준 오차의 과소 추정문제를 보완한 방법
- Hot-Deck 방법
- Nearest Neighbor 방법
(3) 다중 대치법(Multiple Imputation)
- 단순 대치법을 m번 실시하여, m개의 가상적 자료를 만들어 대치하는 방법
02. R의 결측값 처리 관련 함수
| complete.cases() | 데이터 내 레코드에 결측값이 있으면 FALSE, 없으면 TRUE 반환 |
| is.na() | 결측값이 NA 인지의 여부를 TRUE/FALSE 로 반환 |
| DMwR 패키지 : centralImputation() |
NA 값을 가운데 값(Central Value)으로 대치 (숫자-중위수, Factor-최빈값) |
| DMwR 패키지 : knnImputation() |
NA 값을 k최근 이웃 분류 알고리즘을 사용하여 대치 (k개 주변 이웃까지의 거리를 고려하여 가중 평균한 값을 사용) |
| Amelia 패키지 : amelia() |
time-series-cross-sectional data set(여러 국가에서 매년 측정된 자료)에서 활용 |
03. 이상값 처리
(1) 이상값
- 의도하지 않은 현상으로 입력된 값 or 의도된 극단값 → 활용 가능
- 잘못 입력된 값 or 의도하지 않은 현상으로 입력된 값이지만 분석 목적에 부합되지 않는 값 → Bad Data이므로 제거
⇒ 이상값을 꼭 제거해야 하는 것은 아니기 때문에 분석 목적이나 종류에 따라 판단
(2) 이상값의 인식
- ESD(Extreme Studentized Deviation) : 평균으로부터 3표준편차 떨어진 값
- 기하평균-2.5*표준편차 < data < 기하평균+2.5*표준편차
- Q1-1.5*IQR < data < Q3+1.5*IQR 을 벗어나는 데이터(IQR(사분위수범위) = Q3 - Q1)
✔ ESD 알고리즘의 정의 및 "이상값은 무조건 제거하고 분석한다" 오답 출제
(3) 이상값의 처리
- 절단(Trimming) : 이상값이 포함된 레코드 삭제
- 조정(Winsorizing) : 이사값을 상한 또는 하한 값으로 조정
⇒ 조정의 경우, 제거에 비해 데이터 손실율이 낮아 설명력이 높아지는 장점이 있음
'CERTIFICATION > ADsP' 카테고리의 다른 글
| [D-7/핵심포인트 정리] 3과목 데이터 분석(2) (0) | 2024.02.18 |
|---|---|
| [D-7/핵심포인트 정리] 2과목 데이터 분석 기획 (0) | 2024.02.18 |
| [D-7/핵심포인트 정리] 1과목 데이터 이해 (0) | 2024.02.17 |


